Creating Intelligence

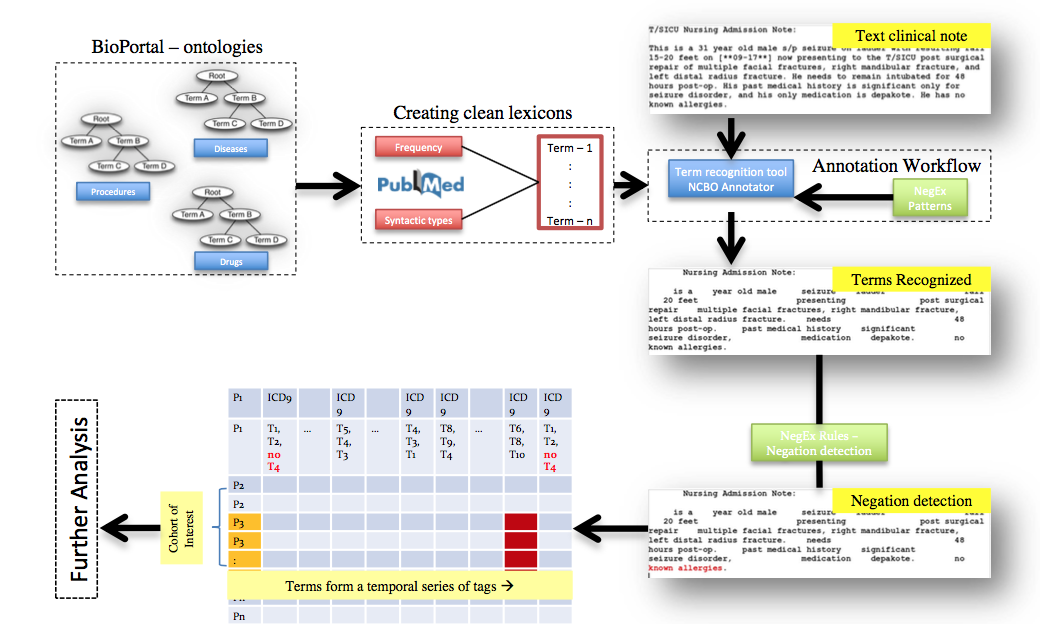
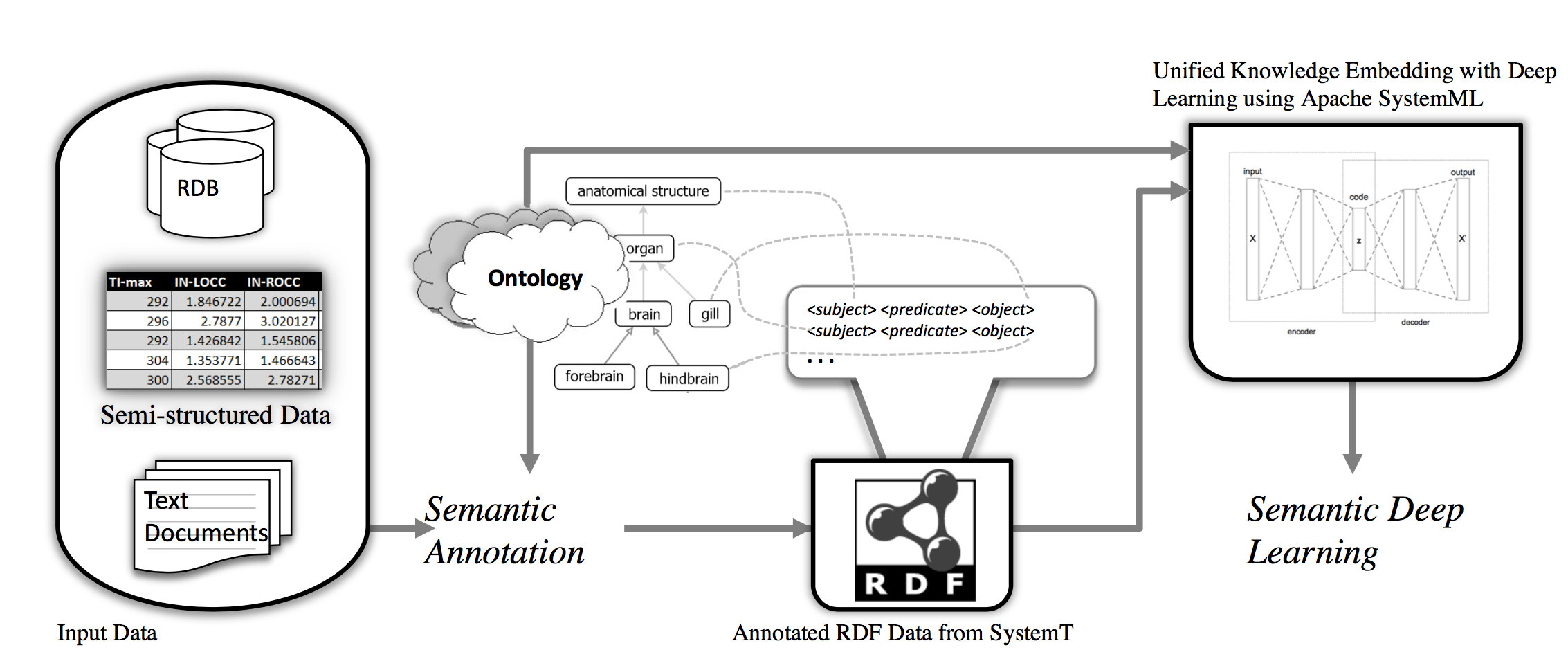
We propose a novel "Semantic Deep Learning" method to analyze the electronic health records of real patients. Our previous work as successfully used a hypergraph- based approach in the clinical text notes from Stanford Hospital’s Clinical Data Warehouse (STRIDE). Previous experiments based on ontology (i.e., domain knowledge) annotated electronic health records show that hypergraph mining is successful in finding semantic (i.e., indirect) associations. This proposed method will take the success to the next level by adding the deep learning-based embedding in place of the basic hypergraphs of the previous approaches. The findings in this study will provide guidance to medical researchers for further investigations. We will create an ontology-based semantic system to combine rule/knowledge embedding and deep learning that better analyze EHRs. Our goal is to devise a novel method for generating biomedical knowledge embedding with Apace SystemML and improve the performance of information extraction systems (e.g., SystemT) in general. The learned embeddings can then be used to find related entities (i.e., closely related drugs that can act as substitutes in case a particular patient has medical complications for a prescribed drug) or entities that are linked by a relation (i.e., diseases which potentially can be treated with a particular drug).
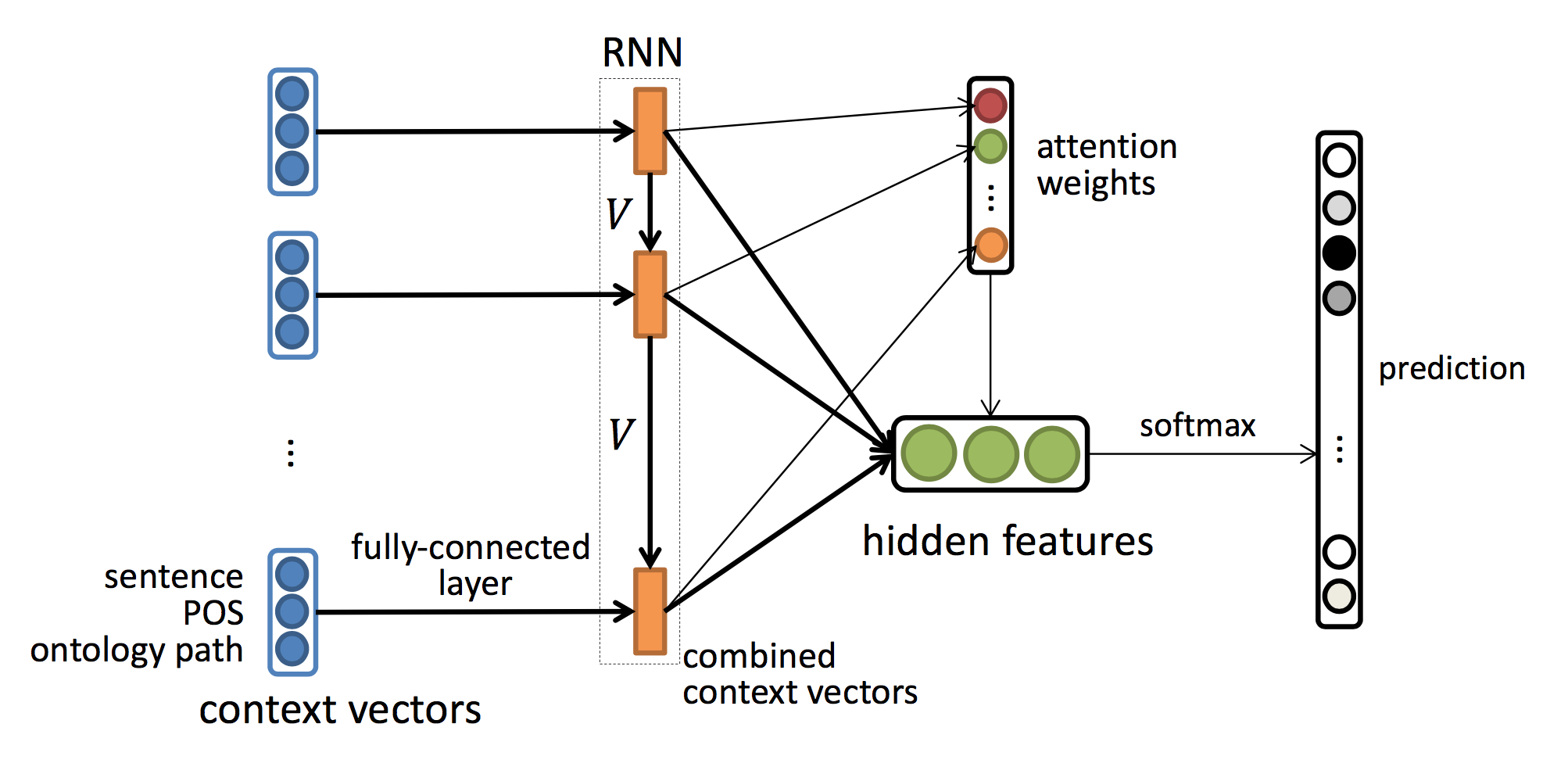
In this project, we will investigate ontology-based deep learning (OBDL) algorithms to predict and explain human behaviors in health domains. The main idea of our algorithms is to consider domain knowledge in the design of deep learning models and utilize domain ontologies for explaining the deep learning models and results. We will focus on specific application in behavior and temporal prediction in health domain. We will extend ontology-based deep (learning) architecture from RBM to other deep learning models, such as RNN and LSTM with temporal information. We will extend OBDL to other application domains related to human behavior prediction, such as Electronic Health Records (PeaceHealth), Drug Information (with Eli Lilly), and Social Medias (with Baidu). We will utilize ontologies to provide more meaningful (semantic) explanations for the deep learning models and results. We can compare our algorithms with state-of-the-art human behavior prediction models, which do not use ontologies. Common deep learning architectures take a flat representation of features as an input. This would introduce bias into representation learning results since uncorrelated features are treated the same with correlated features in the same learning process. Therefore, designing a model that can have the ability to learn the representations of features from domain knowledge is an urgent demand.
In this project, we will design ontology-based interpretable deep models for consumer complaint explanation and analysis. The main idea of our algorithms is to consider domain knowledge in the design of deep learning models and utilize domain ontologies for explaining the deep learning models and results through casual modeling. We will focus on specific application in consumer complaint explanation using Financial Industry Business Ontology (FIBO). The applications of this method can be in various domains, such as financial business, biomedicine, and health informatics. We can keep improving the models by taking into account user feedbacks. We will design unsupervised semantic deep learning models by leveraging deep reinforcement learning, e.g., automatically generating consumer complaints – explanations – verifications.
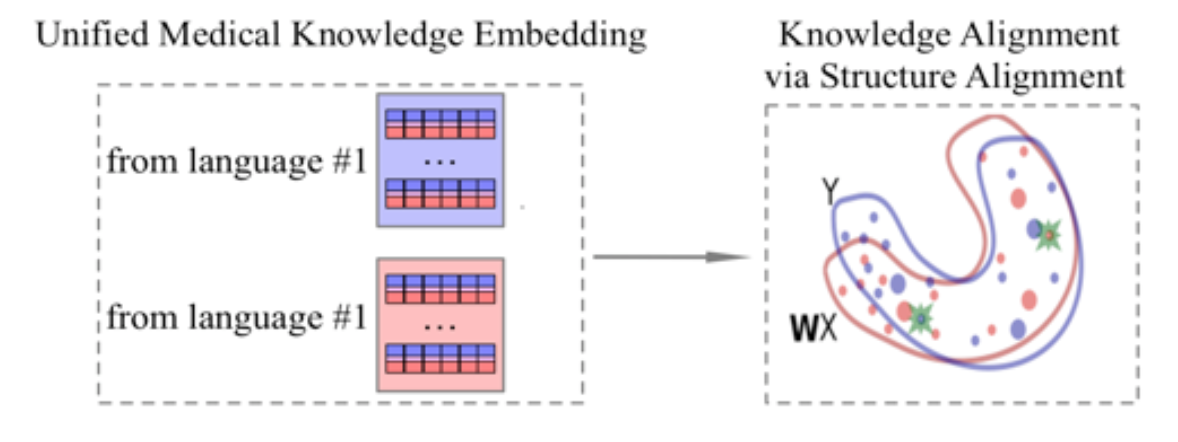
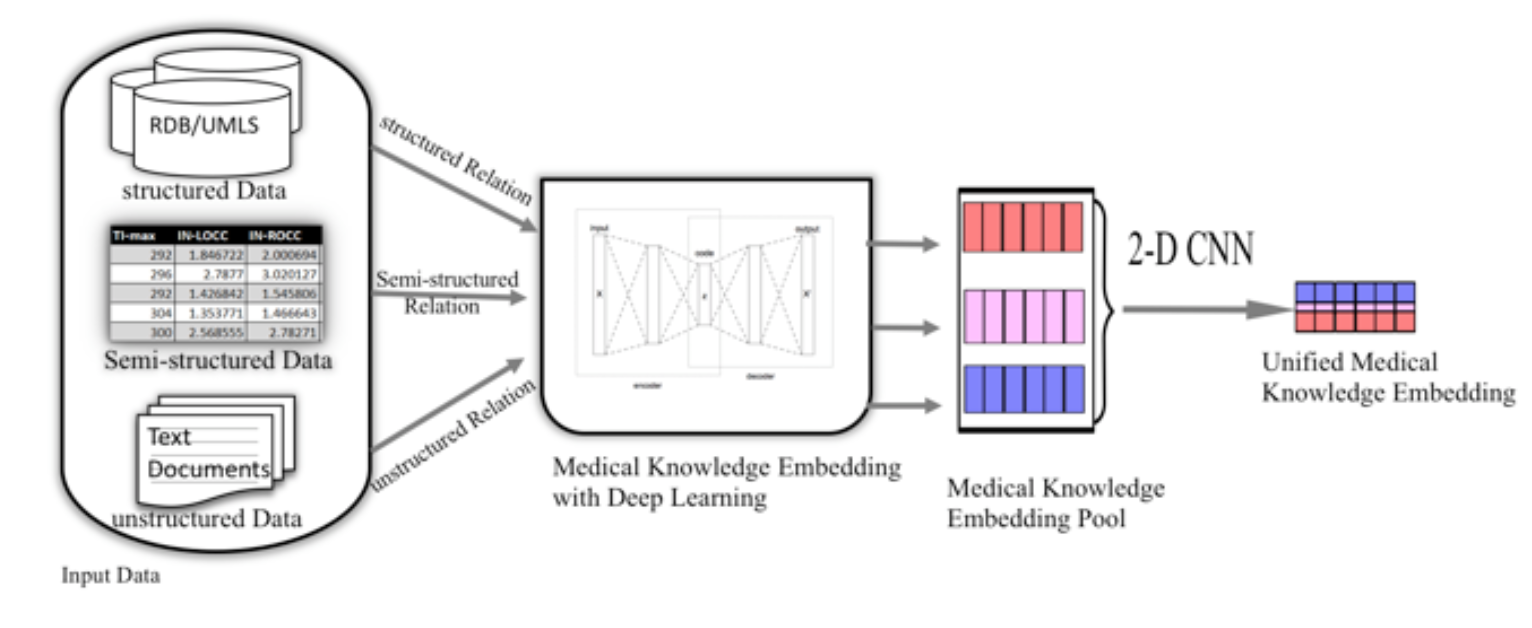
In this project, we will develop innovative medical embedding learning algorithms and make knowledge alignment across multiple languages in the medical domain. Our learning algorithms will fully exploit the semantic similarity for knowledge alignment across languages. Our model will first encode multilingual knowledge into latent embedding semantic spaces, and then make the knowledge aligned by cross-mapping among these embedding spaces. We employ data visualization techniques to help analyzing and designing the embedding learning and space mapping process. We aim at better accuracy than traditional translation based techniques by exploiting semantic information hidden in the knowledge. The application of our aforementioned algorithm enables sharing of medical knowledge across multi-languages and improving the performance of deep learning based diagnosis. We also test the resulted semantic deep learning system for EHR data analysis and diagnosis.
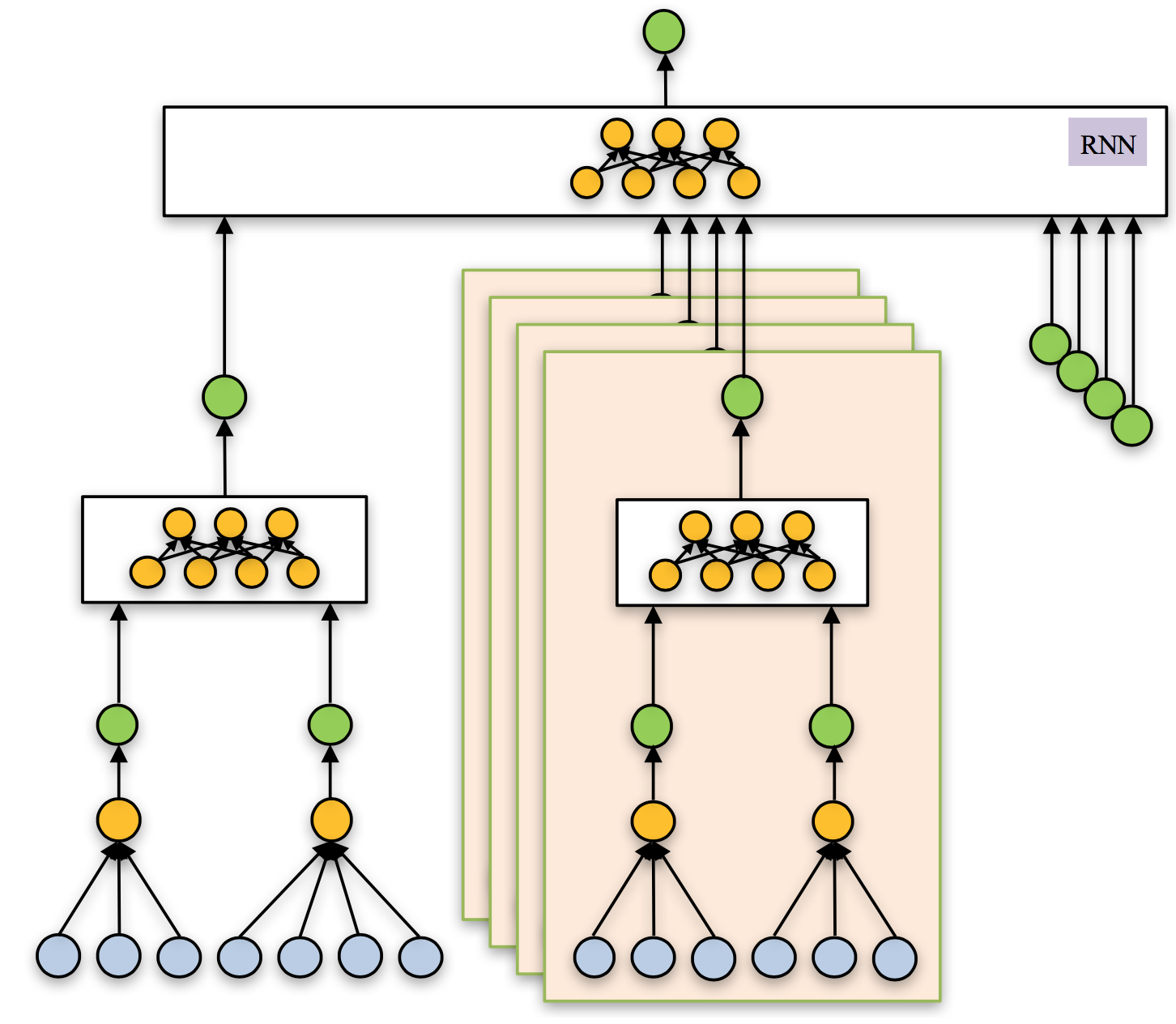
Deep learning poises to transform the landscape of investment in the equity market. In this project, we aim to create a data-driven deep learning model that optimizes the investment strategy in the stock market of the institutional investor. The immediate goal is to improve accuracy in predicting the mid- term outlook of stock return. Also importantly, we aim to create a deep learning model that yield rich contextual information alongside of the output, for supporting decision making and analysis of the institutional investors. Specifically, the model design will preserve the domain know-how of the investor, and the know-how will be preserved through the training process of the model. Furthermore, the model will be transparent, so the decision maker can recover and retrieve vital domain-relevant information from the model output for verification and analysis. So, the model is accountable. Finally, the model will be flexible to accommodate data with heterogeneous types and frequencies and economic logics with various natures. To achieve these objectives, we propose a hierarchical and modularized design of deep learning network. The network consists of multiple layers of sub-networks, each of which is an independent module that captures a piece of economic/financial logic or domain know-how in investment. The sub-network takes as input the output of the lower-layer sub-networks and produces output with economic meaning and importance for the investor. Within a sub-network, the network structure is customized to match the nature of economic/financial logic it represents.
This project is to determine how best to apply Deep Learning to enable advanced scanning technologies to differentiate retail products when presented with a mixture of consumer- packaged goods, produce, and other items (e.g., apparel). As this is an embedded implementation, it will also determine computational power vs accuracy for this application. The Deep Learning enabled system should yield high-accuracy segmentation and coarse classification of retail items when presented with the previously-mentioned mixture. A secondary objective is to explore finer-grained classification within each equivalence class (e.g., distinguish between apples and carrots).
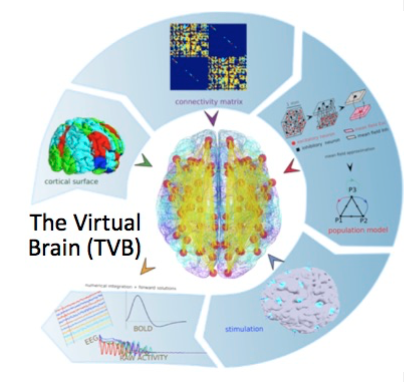
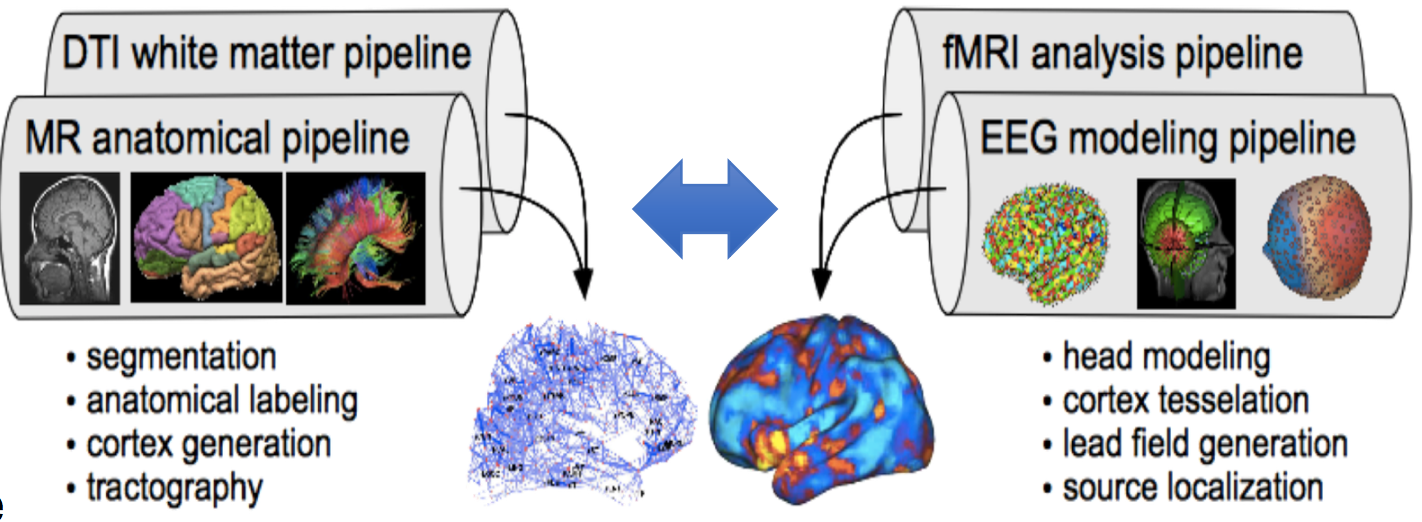
Human brain development and health are important for society. Understanding how the brain works will result in technology to improve learning, maintain or enhance cognitive function, build better assistive brain computer interfaces, and many other applications. Neuroimaging to observe brain activity generates dense temporal/spatial data that contains rich information, but are complex to analyze and interpret. Machine learning holds promise to uncover features in “big data” neuroscience that can lead to new discoveries of brain operation. Furthermore, simulation and modeling of brain components and dynamics could make it possible to refine brain organization and emulate behavior for an individual. The project will investigate the application of ML/DL techniques to the analysis of high-resolution temporal and spatial neurological data in both human and mouse research. Human data will come from dense-array EEG (dEEG) studies. Mouse data will come from the state-of-the-art multiphoton mesoscope. The Virtual Brain technology will be used for neural mass simulation to study brain dynamics, as the project investigates the application of ML/DL techniques to adapting a brain model to better emulate actual neurological function and neurophysiological dynamics.